
Ein Artikel aus der Medienwoche vom 15. Mai 2020. Den Original-Text gibt es hier zu lesen.
---
«Ich studiere Statistik seit über 40 Jahren und verstehe sie immer noch nicht. Die Leichtigkeit, mit der Nicht-Statistiker sie meistern, ist erstaunlich.» Der ironische Kommentar des Biostatistikers Stephen Senn bringt die Problematik des medialen Umgangs mit statistischen Kennzahlen wunderbar auf den Punkt: Hochkomplexe statistische Zusammenhänge werden gerne auf knackige Schlagzeilen und einfach wirkende Empfehlungen verdichtet; Unsicherheiten bleiben unerwähnt oder werden aufgebauscht; unbewiesene Vermutungen verwandeln sich in gesicherte Kausalzusammenhänge.
Erstaunlich ist das nicht. Statistische Informationen verständlich und korrekt zu vermitteln, ist eine Kunst, die mathematisches Können, fachspezifisches Wissen und gestalterisches Geschick verlangt. Die Gefahr, über statistische Fallstricke zu stolpern, ist deshalb gross. Das gilt für unsinnige Vergleiche von Terror- mit Unfalltoten genauso wie für Berichte über den «Durchschnittsschweizer».
Sobald in Medienberichten statistische Kennzahlen ins Spiel kommen, ist Vorsicht geboten. Das zeigt auch die gegenwärtige Berichterstattung zu COVID-19, die besonders anfällig für statistische Stolpersteine ist, weil Infektions- und Todeszahlen sowie epidemiologische Modellierungen eine derart grosse Bedeutung in der öffentlichen Diskussion einnehmen. Viele Journalisten sind sich dessen bewusst. Die «Republik» veröffentlichte beispielsweise eine Erklärung, wie sie mit wissenschaftlichen Informationen rund um COVID-19 umgehen. In der NZZ erschien ein Artikel, der die bisweilen intransparenten Berechnungen und Modelle von Medien und Forschungseinrichtungen zum Schätzen der genesenen Patienten kritisierte. Und auch im Wissen-Teil des «Tages-Anzeigers» erschien ein Artikel über die Herausforderungen beim Lesen von Corona-Statistiken.
Darauf aufbauend möchte ich einige Punkte ausführen, auf die es zu achten gilt, wenn Medien Statistiken verwenden – illustriert anhand positiver und negativer Beispiele im Zusammenhang mit der aktuellen Corona-Berichterstattung. Beispiele, die weder für die Medienlandschaft als Ganzes, noch für die erwähnten Publikationen repräsentativ sind.
Es handelt sich also nicht um eine systematische Analyse der Qualität von Statistiken in Schweizer Medien. Das würde sowohl meine zeitlichen Ressourcen wie auch meine wissenschaftliche Kompetenz übersteigen, weshalb ich diese Aufgabe Experten wie jenen vom Forschungszentrum «Öffentlichkeit und Gesellschaft» der Universität Zürich mit ihrem Jahrbuch «Qualität der Medien» überlasse.
Die nachfolgenden Beispiele dienen lediglich als Illustration zu den Fragen, die ich aufwerfe. Diese Unterscheidung zwischen Anschauungsbeispielen einerseits und repräsentativen Aussagen andererseits ist dann auch bereits die erste wichtige Lektion, die es beim Umgang mit statistischen Informationen zu verinnerlichen gilt: Ein illustratives Beispiel ist keine repräsentative Untersuchung, eine Anekdote kein Beweis.
Wird eine Quelle angegeben?
Nachvollziehbare und überprüfbare Quellen sind zur Einschätzung von statistischen Kennzahlen immer notwendig. Wenn ich als Leser dazu keine Angaben erhalte, sollte ich sie mit sehr viel Vorsicht geniessen – schliesslich kann ich nicht überprüfen, in welchem Zusammenhang die Daten ursprünglich erhoben oder verwendet worden sind. Wenn der «Blick» und der «Tages-Anzeiger» in Artikeln zum möglichen Zusammenhang zwischen Luftverschmutzung und COVID-19-Todesfällen auf «eine Studie von US-Forschern der Harvard-Universität» verweisen, dann ist das zu unspezifisch, um als Quellenangabe gelten zu dürfen.
Zusammen mit den im Artikel gemachten Angaben, der Kenntnis der richtigen Suchmaschinen und ein bisschen Geduld lassen sich zwar die meisten Studien ausfindig machen. Doch Detektivarbeit sollte zum Überprüfen von Studien nicht notwendig sein – Journalisten sollten diese Informationen von sich aus liefern. Wie einfach das geht, zeigt ein Artikel von Ruth Fulterer in der NZZ, der das gleiche Thema und dieselben Studien behandelt wie die beiden oben erwähnten Artikel in «Blick» und «Tages-Anzeiger». Die Leserinnen und Leser erfahren nicht nur, wer die Studienautoren waren, sondern können den Inhalt der Studien dank der im Artikel gesetzten Links mit einem einzigen Klick selber überprüfen.
(Wie) wurden Zahlen erhoben oder geschätzt?
Ein Verweis auf eine Quelle sagt noch wenig darüber aus, wie Statistiken und Zahlen erhoben oder geschätzt worden sind. Meist ist das in der Ursprungspublikation beschrieben, aber Medienschaffende sollten die wichtigsten Informationen dazu auch in ihrem Artikel angeben, damit die Leserinnen und Leser dies bei der Interpretation der Zahlen mitberücksichtigen können.
Eine Statistik, die es seit Ausbruch der Epidemie regelmässig auf Titelseiten schafft, ist jene der bestätigten Infektionen. Unerwähnt bleibt dabei allzu oft, dass die Zahl der offiziell bestätigten COVID-19-Fälle nicht die Gesamtzahl der tatsächlich mit SARS-CoV-2 infizierten Menschen darstellt, sondern diese systematisch unterschätzt. Einerseits werden in vielen Ländern vorwiegend Risikopatienten und Patienten mit starken Symptomen getestet, andererseits dauert es eine gewisse Zeit, bis infizierte Menschen Symptome entwickeln und überhaupt auf die Idee kommen, sich testen zu lassen. Die NZZ erwähnt dies explizit auf ihrer COVID-19-Übersichtsseite (Stand 6. Mai, 18h00) und verlinkt zudem zwei Hintergrundartikel, die teilweise erklären, wie die nationalen und internationalen COVID-19-Zahlen erhoben werden. Auf der entsprechenden Übersichtsseite des «Tages-Anzeigers» fehlen solche Hinweise (Stand 6. Mai, 18h00). Wie COVID-19-Fälle medizinisch bestätigt werden und was einen bestätigen von einem unbestätigten Fall unterscheidet, wird aber weder auf dem Übersichtsartikel der NZZ noch auf jenem des «Tages-Anzeigers» erklärt.
Die Zahl derjenigen, die an COVID-19 gestorben sind, ist eine zweite Statistik, die Eingang in viele Medienberichte findet. Und auch diese Zahl ist mit grossen Unsicherheiten behaftet. In gewissen Ländern – die Schweiz eingeschlossen (PDF) – werden Verstorbene nur dann als COVID-19-Todesfälle gezählt, wenn ein labordiagnostischer Test auf SARS-CoV-2 vorliegt. Wer also beispielsweise in einem Altersheim verstirbt, ohne auf SARS-CoV-2 getestet worden zu sein, taucht nicht in der offiziellen Statistik der COVID-19-Todesfälle auf. In anderen Ländern – zum Beispiel in Belgien – werden auch jene Todesfälle COVID-19 zugerechnet, bei denen lediglich der Verdacht auf eine Infektion mit SARS-CoV-2 vorliegt. Im ersten Fall wird die Zahl der Toten wahrscheinlich unter-, im zweiten Fall wohl überschätzt. Wie stark, lässt sich erst nach einer gewissen Zeit feststellen.
Auch innerhalb eines Landes kann es wesentliche Unterschiede in den offiziellen Statistiken geben. In Grossbritannien wurden in den täglich veröffentlichten Todesfall-Statistiken bis Ende April nur Patienten aufgeführt, die im Spital verstorben waren. In den wöchentlich veröffentlichten Statistiken wurden jedoch auch labordiagnostisch bestätigte Todesfälle ausserhalb von Spitälern erwähnt sowie Todesfälle, bei denen COVID-19 aufgrund der Symptomatik als Ursache vermutet wurde, aber keine labordiagnostische Bestätigung vorlag. Vor diesem Hintergrund sind auch Vergleiche der Todesfälle zwischen den Ländern mit Vorsicht zu geniessen.
Leider wird dies weder auf der Übersichtsseite des «Tages-Anzeigers» noch auf jener der NZZ thematisiert. Im Gegenteil: Die NZZ behauptet sogar, dass die Todeszahlen verlässlicher seien als die bestätigten Fallzahlen, «wo es grosse Unsicherheiten wie unterschiedliche Zählweise und hohe oder niedrige Testing-Intensität» gebe. Dieselben Vorbehalte sind aber, wie oben aufgezeigt, auch beim Vergleich der Zahl der Todesfälle angebracht. In vielen Ländern gilt ein Verstorbener nur dann als COVID-19-Todesfall, wenn er vor dem Ableben positiv auf SARS-CoV-2 getestet wurde.
Die dritte Statistik, die gerne zusammen mit der Zahl der Infizierten und der Toten genannt wird, ist jene der Genesenen. Diese Zahl wird in kaum einem Land systematisch erhoben und muss deshalb meist geschätzt werden. Insofern ist es problematisch, unterschiedlich erhobene oder geschätzte Statistiken nebeneinander zu stellen, ohne explizit auf die vorhandenen Unterschiede bei der Herkunft hinzuweisen. Die Lesenden erhalten so den falschen Eindruck, dass die Art der Datenerhebung und die damit zusammenhängende Verlässlichkeit bei den verschiedenen Zahlen dieselbe ist.
Sowohl die NZZ als auch der «Tages-Anzeiger» vermerken bei den meisten (aber nicht allen) Grafiken, dass die Zahl der Genesenen auf Schätzungen beruht und tun dies mal mehr, mal weniger deutlich. Die NZZ hat den Berechnungsgrundlagen überdies einen eigenen Artikel gewidmet, der auch auf der Übersichtsseite verlinkt ist und der die dazugehörigen Modelle für alle zugänglich macht. Demgegenüber beschränkt sich die Übersichtsseite beim «Tages-Anzeiger» auf den Verweis, dass die Zahl der Genesenen basierend auf den Erkenntnissen zu Krankheitsdauer und Anteil milder und schwerer Fälle am Total der Fälle berechnet werde. Das ist besser als gar keine Angabe, verunmöglicht aber eine Überprüfung der Berechnungen und der zugrundeliegenden Annahmen.
Werden die verwendeten Zahlen (korrekt) kontextualisiert?
Komplexe statistische Sachverhalte auf eine einzelne Kennzahl herunterzubrechen, geht fast immer schief. Das zeigt sich auch im Fall des bereits erwähnten NZZ-Artikels zu einem möglichen Zusammenhang von Luftverschmutzung und COVID-19-Todesfällen. Die Autorin schreibt, dass «jedes Mikrogramm [Feinstaub] pro Kubikmeter Luft die Covid-19-Sterberate um 15 Prozent» erhöhe. Eine Information, die im besten Fall wenig informativ und im schlimmsten Fall irreführend ist. Um diese Prozentzahl als Leser einschätzen zu können, müsste man zumindest wissen,
wie viele Mikrogramm Feinstaub normalerweise in der Luft zirkulieren;
über welchen Zeitraum eine erhöhte Konzentration gegeben sein muss, um zu schaden;
welchen Schwankungen die Feinstaubbelastung normalerweise unterliegt;
wie stark der Einfluss anderer Risikofaktoren auf das Sterberisiko durch COVID-19 ist.
Hinzu kommt, dass sich ohne Kenntnisse der Grundsterberarte nicht sagen lässt, was eine Erhöhung der Tödlichkeit um 15 Prozent überhaupt bedeutet. Gehen wir davon aus, dass durchschnittlich 1 Prozent der mit SARS-CoV-2 infizierten Menschen sterben. Das würde bedeuten, dass von 10'000 Infizierten 100 an COVID-19 sterben – ein relativer Anstieg dieser Rate um 15 Prozent würde dementsprechend zu 15 mehr Toten führen. Läge die durchschnittliche Tödlichkeit hingegen bei 0.1 Prozent (10 Tote auf 10'000 Infizierte), dann würde ein relativer Anstieg um 15 Prozent lediglich zu 1.5 mehr Toten führen; bei einer Grundrate von 10 Prozent (1000 Tote auf 10'000 Infizierte) wären es hingegen 150 Tote mehr. Dieselbe relative Erhöhung der Tödlichkeit (15 Prozent) hat bei unterschiedlichen Grundraten (0.1 Prozent, 1 Prozent oder 10 Prozent) also ganz unterschiedliche Bedeutungen in Bezug auf die Erhöhung der zu erwartenden Todeszahlen (1.5, 15 oder 150 Tote mehr auf 10'000 Infizierte).
Sind Grafiken auch für Laien verständlich?
Grundsätzlich gilt: Grafiken richtig zu lesen, braucht Übung. Je mehr Medienschaffende ihre Leserinnen und Leser dabei unterstützen können, desto besser. Zu einer verständlichen statistischen Grafik gehören sauber beschriftete Achsen, übersichtliche Legenden und prägnante Erläuterungen, die den Lesenden erklären, was sich in der Darstellung erkennen lässt. In dieser Hinsicht sind die Corona-Übersichtsseiten von NZZ und «Tages-Anzeiger» (Abo+) grundsätzlich solide, es gibt aber Ausreisser zum besseren und zum schlechteren.
Positiv hervorzuheben ist jene Darstellung des «Tages-Anzeigers», welche die kumulative Zahl der bestätigten COVID-19-Fälle der Schweiz im Vergleich mit anderen Ländern zeigt. Die Achsen und Legenden sind verständlich beschriftet und gestrichelte Trendlinien in der Grafik lassen die Lesenden auf einen Blick erkennen, wie rasch sich die Zahl der Fälle in den einzelnen Ländern und zu unterschiedlichen Zeitpunkten ungefähr verdoppeln.

All jene, die mehr zu den Begebenheiten in den einzelnen Ländern erfahren möchten, erhalten zudem über eine aufklappbare Textbox weitere Informationen.
Abgerundet wird das Ganze mit dem expliziten Hinweis, dass die Daten auf der vertikalen Achse logarithmisch aufgetragen sind, und einer Erklärung, wie logarithmischen Skalen zu interpretieren sind. Solche «Leseanleitungen» sind essentiell für das Verständnis der Lesenden, die keine Erfahrung im Umgang mit solchen Darstellungen haben.
Doch auch bei dieser Grafik gibt es Verbesserungspotential. So sollte beispielsweise angeben werden, woher die verwendeten Daten stammen, sowie, dass es bei den Teststrategien der einzelnen Länder erhebliche Unterschiede geben kann, was sich auch auf die Fallzahlen auswirkt.
Als Negativbeispiel muss eine Grafik der NZZ herhalten, in der die Zahlen der täglichen Todesfälle in unterschiedlichen Ländern miteinander verglichen werden.

Die vertikale Achse scheint bei jedem Land unterschiedlich skaliert zu sein und es ist auch nicht angegeben, ob es sich um eine logarithmische oder lineare Skala handelt. Und da auf jeder einzelnen Grafik nur jeweils zwei Werte angegeben sind, lässt sich diese Information auch nicht ablesen. Ebenso wenig ist in der Legende ersichtlich, dass die horizontale Linie in den Grafiken den Durchschnittswert der vergangenen sieben Tage darstellen soll. All dies erschwert die Interpretation und Vergleichbarkeit enorm. Positiv zu erwähnen ist jedoch, dass der statistische Ausreisser bei den Todesfällen in China erklärt wird und die Datenquellen ausgewiesen sind.
Werden Fachbegriffe erklärt?
Nicht nur Grafiken, auch Fachausdrücke wollen erläutert werden. Denn was es mit Begriffen wie «Reproduktionszahl», «Verdopplungszeit», «Median» oder «Konfidenzintervallen» auf sich hat, wissen nicht alle Lesenden gleichermassen.
Sowohl die NZZ wie auch der «Tages-Anzeiger» erklären, dass die Schwelle zum exponentiellen Wachstum bei einer Reproduktionszahl von über 1 erreicht ist – aber nur der «Tages-Anzeiger» weist darauf hin, dass die Angabe einer Verdopplungszeit streng genommen nur bei einem exponentiellen Wachstum sinnvoll ist. Die NZZ verlinkt demgegenüber ein eigenes Glossar, das regelmässig aktualisiert wird und viele Fachbegriffe im Zusammenhang mit der Corona-Pandemie erklärt.
Was ein Median ist und inwiefern er sich vom arithmetischen Mittel unterscheidet, wird jedoch weder vom «Tages-Anzeiger» noch von der NZZ erklärt. Das ist insofern problematisch, als die beiden Kennzahlen gerne vermischt werden. Der Median ist jener Wert, der eine Zahlenmenge so unterteilt, dass die eine Hälfte der Zahlen kleiner, die andere Hälfte grösser ist als der Median. Das arithmetische Mittel (umgangssprachlich auch «Durchschnitt» genannt) ist die Summe einer Zahlenmenge geteilt durch die Anzahl der einzelnen in der Menge vorhandenen Zahlen. Der Median ist weniger anfällig auf statistische Ausreisser als das arithmetische Mittel, weshalb es für die Interpretation wichtig ist zu wissen, wovon die Rede ist. Wenn drei Menschen ohne Vermögen an einem Tisch sitzen, liegt sowohl das Median- wie auch das Durchschnittsvermögen bei 0 CHF. Wenn sich Bill Gates dazugesellt, sitzen im Durchschnitt auf einen Schlag Multimilliardäre am Tisch, die im Median aber weiterhin arme Schlucker ohne Vermögen sind.
Wirklich komplex wird es beim Konfidenzintervall. Leicht verständliche Erklärungen dieses statistischen Konzepts sind schwierig zu finden. Das mag auch daran liegen, dass korrekte Beschreibungen sehr technisch wirken. Eine einigermassen verständliche Beschreibung für Laien stammt aus den Kommentarspalten des Blogs des Statistikers Andrew Gelman: Ein Leser vergleicht dort ein 95-Prozent-Konfidenzintervall mit der Zuverlässigkeit eines Schützen, der in 95 von 100 Fällen sein Ziel trifft. Salopp gesagt: Bei 95 von 100 95-Prozent-Konfidenzintervallen können wir erwarten, dass der tatsächliche Wert, den wir mit unseren Statistiken versuchen zu schätzen, im Intervall enthalten ist. Wie sehr das statistischen Laien tatsächlich hilft, die damit verbundenen Unsicherheiten zu verstehen, ist jedoch fraglich. Gegenfalls wäre es besser, den Begriff des Konfidenzintervalls wegzulassen und sich darauf zu konzentrieren, explizit auf die mit jeder statistischen Schätzung einhergehenden Unsicherheiten zu verweisen.
Werden Zahlen und Statistiken aus verschiedenen Blickwinkeln präsentiert?
Einzelne statistische Kennzahlen können schnell in die Irre führen, wenn sie nicht korrekt kontextualisiert werden. Aus diesem Grund ist es sinnvoll, Zahlen und Statistiken aus unterschiedlichen Blickwickeln darzustellen.
Um das ganze Ausmass der COVID-19-Epidemie fassbar machen zu können, aber gleichzeitig die visuelle Vergleichbarkeit aufrechtzuerhalten, wäre es für Lesende beispielsweise sehr nützlich, wenn sie selbständig zwischen logarithmischer und linearer Darstellung der Daten hin- und herwechseln könnten und nicht nur die absoluten Fallzahlen, sondern auch die Fallzahlen relativ zur Bevölkerungszahl betrachten könnten. Auf der vom Chemie-Informatiker Daniel Probst erstellten Übersichtsseite corona-data.ch ist dies im Gegensatz zu den Übersichtsseiten von NZZ und «Tages-Anzeiger» einfach möglich.
Was das Verständnis und die Einordnung der behandelten Daten weiter unterstützen kann, aber für die Datenjournalisten zugegebenermassen mit beträchtlich mehr Aufwand verbunden ist, sind komplett interaktive Darstellungen. Damit kann ich als Leser jene statistischen Zusammenhänge genauer betrachten, die mich am meisten interessieren. Der Mehraufwand für die Datenjournalisten ist dabei nicht nur technischer, sondern auch inhaltlicher Natur: Interaktive Darstellungen sind nicht nur aufwändiger zu erstellen, sondern auch aufwändiger zu erklären.
Werden die Ergebenisse statistischer Tests korrekt wiedergegeben?
Statistische Fachbegriffe werden gerne, aber nur selten richtig, verwendet. Ein Paradebeispiel dafür ist der Begriff der «Signifikanz». Umgangssprachlich ist ein Ergebnis dann signifikant, wenn es von praktischer Bedeutung ist. In der Statistik bedeutet ein signifikantes Ergebnis erst einmal nur, dass ein bestimmter Schwellenwert überschritten wurde.
Sogenannte «Signifikanztests» werden durchgeführt, um einschätzen zu können, wie unerwartet ein bestimmtes wissenschaftliches Ergebnis unter bestimmten Annahmen ist. Dazu werden gewisse statistische Eigenschaften der erhobenen Daten berechnet (z.B. das arithmetische Mittel), um diese dann mit Werten zu vergleichen, die basierend auf den getroffenen Grundannahmen zu erwarten gewesen wären. Wenn die berechneten Werte eine vordefinierte Schwelle überschreiten, reden Forschende von einem «statistisch signifikanten» Ergebnis, was aber oft nicht viel mehr bedeutet, als dass es sich lohnt, genauer hinzuschauen.
Das Überschreiten einer statistischen Signifikanzschwelle sagt für sich genommen nichts über die Stärke des gemessenen Effekts oder über die Bedeutung der Ergebnisse aus. Auch sehr kleine und wissenschaftlich uninteressante Effekte können statistisch signifikant sein. Erschwerend kommt hinzu, dass ich garantiert ein statistisch signifikantes Ergebnis erhalte, wenn ich nur genügend solcher Tests durchführe und dies in der Analyse nicht entsprechend mitberücksichtige. Ein Journalist hat mit dieser Methode sogar einmal «bewiesen», dass Schokolade beim Abnehmen hilft. Er hat einfach so viele verschiedene Tests durchgeführt, bis einer davon zufälligerweise signifikant ausfiel. Wer selber versuchen möchte, solche zufälligen signifikanten Resultate zu produzieren, der kann das ganz leicht mittels einer entsprechende Simulation auf «FiveThirtyEight» tun.
Beim weiter oben diskutierten Zusammenhang zwischen Luftverschmutzung und COVID-19-Todesfällen wäre deshalb zu überprüfen, wie viele Tests die Forschenden durchgeführt haben. Haben sie nur die Feinstaub- und Stickoxidbelastung untersucht? Oder haben sie zusätzlich noch Kohlenwasserstoffe, Schwefeloxide, Ozonbelastung und andere Luftschadstoffe getestet, aber nur über jene Resultate berichtet, die sich als signifikant herausgestellt haben?
Kurz: Nicht jedes statistisch signifikante Resultat ist wissenschaftlich relevant. Weil COVID-19 zurzeit von allen nur erdenklichen Seiten erforscht wird und die gleichen Tests bisweilen parallel von verschiedenen Forschenden mehrmals durchgeführt werden, akzentuiert sich die Gefahr von statistischen Zufallsbefunden ohne wissenschaftliche Relevanz. Das müsste auch bei der Berichterstattung über neue Forschungsergebnisse explizit berücksichtigt werden.
Ebenfalls weit verbreitet ist der umgekehrte Fehler, nämlich aus einem nicht-signifikanten statistischen Ergebnis voreilig die Abwesenheit eines relevanten Zusammenhangs zu schliessen. In diese Falle tappt beispielsweise Daniel Probst, der Mann hinter corona-data.ch mit seiner Darstellung des Zusammenhangs von Bevölkerungsdichte und der Anzahl der bestätigten Infektionen.

Der verwendete Test ist zwar nicht signifikant, doch weil das dafür verwendete statistische Mass nur für lineare Zusammenhänge geeignet ist, lässt sich daraus nicht schliessen, dass zwischen Bevölkerungsdichte und Infektionszahlen kein Zusammenhang besteht. Unterscheidet man jedoch zwischen Kantonen der lateinischen und der deutschen Schweiz, dann erscheint ein leichter linearer Zusammenhang durchaus plausibel.

Ein anderes Beispiel ist die Studie zur Virenbelastung bei Kindern, die eine Gruppe um den deutschen Virologen Christian Dorsten durchgeführt hat und die auch hierzulande für Diskussionen gesorgt hat. Die Studie wurde erst – auch von den Autoren selber – als Beleg dafür gewertet, dass kein signifikanter Unterschied zwischen der viralen Belastung von Kindern und Erwachsenen besteht. Rein technisch war dieser Schluss basierend auf verwendeten Tests korrekt. Doch wer sich die einzelnen Effektgrössen samt den dazugehörigen Unsicherheitsbereichen anschaute, der erkannte, dass die Virenbelastung bei Kindern im Durchschnitt tiefer war als bei Erwachsenen.
Auf Twitter hat ein Statistiker explizit darauf hingewiesen, doch die damit zusammenhängenden Nuancen gingen in der medialen Berichterstattung komplett verloren. Der «Blick» titelte unter Berufung auf die Studie «Kinder vermutlich genauso ansteckend wie Erwachsene». Der «Tages-Anzeiger» schrieb «Kinder könnten genauso ansteckend sein wie Erwachsene» und in der NZZ hiess es fälschlicherweise, «die Zahl der Viren, die sich in den Atemwegen nachweisen liessen, unterscheide sich bei verschiedenen Altersgruppen nicht». Immerhin wurde darauf verwiesen, dass es sich um eine noch ungeprüfte Vorabveröffentlichung handelte.
In der Zwischenzeit hat eine Neuanalyse durch den Biostatistiker Leonhard Held von der Universität Zürich ergeben, dass bei Verwendung anderer Auswertungsmethoden ein moderater Zusammenhang zwischen dem Alter und der Virenbelastung festgestellt werden kann. Bis zum jetzigen Zeitpunkt (15. Mai, 22h00), haben aber weder «Tages-Anzeiger», noch «Blick» noch NZZ darüber berichtet – nur die CH-Media-Tageszeitungen haben die Analyse aufgegriffen.
Werden bestehende Unsicherheiten (richtig) wiedergegeben?
Unsicherheiten können viele Ursachen haben:
Zufällige Schwankungen: Besonders bei kleinen Stichproben ist Vorsicht bei der Interpretation geboten, da die berechneten Kennzahlen stärker um den tatsächlichen Wert schwanken als bei grossen Stichproben. Aus diesem Grund sollte nie über eine einzelne Studie berichtet werden, ohne diese in den Kontext mit andern Untersuchungen des gleichen Themas zu setzen. Noch besser wäre es, sich auf systematische Zusammenfassungen der wissenschaftlichen Literatur zu diesem Thema zu stützen.
Systematische Verzerrungen: In der Schweiz wurden hauptsächlich Risikopatienten und Menschen mit einem schweren Krankheitsverlauf auf SARS-CoV-2 getestet. Die getesteten Personen stellen also keine zufällige Auswahl der Gesamtbevölkerung dar. Repräsentative Untersuchungen wie jene der Universität Genf versuchen, diese Verzerrungen zu beheben.
Wissenschaftliche Unklarheiten: SARS-CoV-2 wird seit weniger als 6 Monaten wissenschaftlich untersucht. Die wissenschaftliche Forschung bewegt sich deshalb in vielerlei Hinsicht auf unbekanntem Gebiet. Die involvierten Wissenschaftler müssen laufend dazulernen und alte Hypothesen mit neuen Daten abgleichen. Demgegenüber wird etwa der Zusammenhang von CO2 auf die globalen Durchschnittstemperaturen schon seit Jahrzehnten untersucht – entsprechend besser abgestützt sind die entsprechenden wissenschaftlichen Ergebnisse.
Menschliche Fehler: Auch Wissenschaftler sind nur Menschen und können Fehler begehen. Aus diesem Grund ist es entscheidend, dass wissenschaftliche Publikationen kritisch von anderen Fachleuten begutachtet werden («Peer Review»). Das ist noch keine Garantie, dass alle Fehler erkannt wurden, aber Veröffentlichungen, die noch nicht von anderen Fachleuten begutachtet wurden, sollten sehr vorsichtig ausgelegt werden. Im Zusammenhang mit COVID-19 sollten Medienschaffende das ganz besonders berücksichtigen. Aufgrund des Zeitdrucks werden viele neue Ergebnisse als sogenannte «Pre-Prints» veröffentlicht und damit meist ohne vorangehende Überprüfung durch andere Forschende. Mit allergrösster Vorsicht zu geniessen sind Publikationen, bei denen die Forschenden sich zuerst mittels einer Medienmitteilungen an die Öffentlichkeit wenden, also bevor andere Wissenschaftler überhaupt die Möglichkeit hatten, die Ergebnisse zu überprüfen. Aufgrund des gesteigerten Zeitdrucks gehört dieses «science by press release» oder «science by press conference» bei der Forschung zu COVID-19 fast schon zur Normalität. Ein Beispiel dafür ist die Pressemitteilung der Universität Genf zu den ersten Ergebnissen ihrer Antikörperstudie. Die Medienmitteilung mit den Resultaten wurde bereits am 22. April veröffentlicht, der Pre-Print mit den detaillierten Angaben zur Methodik und zur Erhebung der Daten erst am 6. Mai. Immerhin teilte die Studienleiterin Silvia Stringhini auf Twitter das Studienprotokoll noch am Tag der Medienmitteilung und wies durchaus selbstkritisch auf die Schwierigkeit hin, den enormen politischen Druck nach zügigen Resultaten in Einklang zu bringen mit solider und seriöser Überprüfung der Daten.
In der medialen Berichterstattung über wissenschaftliche Informationen kann die korrekte Vermittlung solcher Unsicherheiten in zwei Richtungen schiefgehen: Übertriebene Gewissheit auf der einen, aufgeblasene Unsicherheit auf der anderen. Auf der Strecke bleibt eine differenzierte Einordnung und Interpretation von Daten mit den dazugehörigen Unsicherheiten. Lobenswerte Ausnahmen im Zusammenhang mit COVID-19 ist der Artikel des «Atlantic»-Journalisten Ed Yong zu den vielen Unwägbarkeiten im Umgang mit der Pandemie oder der Text von Maggie Koerth, Laura Bronner und Jasmine Mithani zur Schwierigkeit, ein gutes COVID-19-Modell zu erstellen.
Die Berücksichtigung von Unsicherheiten ist auch bei COVID-19-Übersichtsseiten wie jenen der NZZ oder des «Tages-Anzeigers» entscheidend. Nicht in jedem Land wird auf die gleiche Art und im gleichen Ausmass auf SARS-CoV-2 getestet und auch die Todesfälle werden unterschiedlich erfasst. Das bedeutet, dass die Zahlen nicht auf den Einzelfall vergleichbar sind. Doch die detaillierten Zahlen bei der NZZ wie auch jene beim «Tages-Anzeiger» suggerieren eine Genauigkeit bei der Datenerhebung, die so nicht gegeben ist. Eine Möglichkeit, dies zu adressieren, bestünde beispielsweise darin, nur auf den nächsten Tausender oder Zehntausender gerundete Zahlen zu publizieren – mit dem expliziten Verweis, dass die genauen Infektionszahlen in der gegenwärtigen Lage kaum zu eruieren seien.
Was ebenfalls relevant ist und was auch von Journalisten vermittelt werden sollte, ist der Umstand, dass statistische Schätzwerte selbst dann mit Unsicherheiten verbunden sind, wenn keine systematischen Verzerrungen vorliegen. Bei der Darstellung der wöchentlichen Todeszahlen hat das ganz gut geklappt. Sowohl bei der NZZ wie auch auch beim «Tages-Anzeiger» (Grafik unten) wird um die wöchentlichen Durchschnittswerte eine Bandbreite mit «zu erwartenden» Todesfällen dargestellt
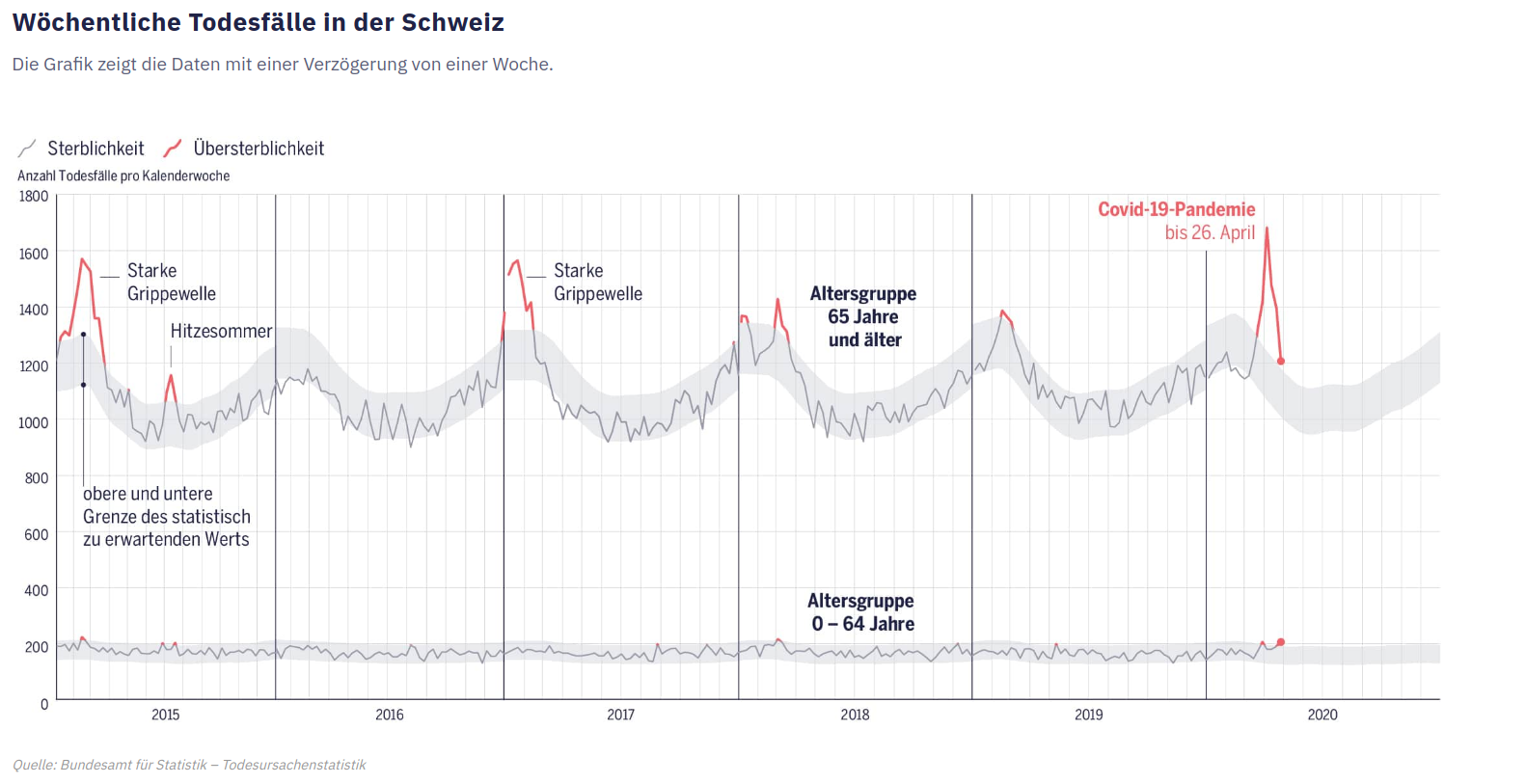
Es bleibt zwar unklar, wie dieser Wert berechnet wurde, basierend auf welchen Annahmen die Grenzen gezogen wurden und um welche Art von Unsicherheitsbereich es sich handelt, beziehungsweise was als «normal» bzw. «zu erwartend» zu interpretieren ist. Diese Informationen erhält nur, wer sich auf der Website des Bundesamts für Statistik schlau macht. Doch die Lesenden erhalten auf einen Blick die entscheidende Kernaussage vermittelt, dass bei den wöchentlichen Todeszahlen mit gewissen statistischen Schwankungen zu rechnen ist und dass diese Schwankungen sich mit einer gewissen Wahrscheinlichkeit im angegebenen Rahmen bewegen.
Werden Äpfel mit Birnen verglichen?
Zwischen den von der Corona-Epidemie betroffenen Ländern gibt es bisweilen grosse Unterschiede in Bezug auf die Bevölkerungsstruktur, -dichte und -verteilung. Diese Faktoren haben genauso einen Einfluss auf den Verlauf der Epidemie wie der Zustand des Gesundheitswesens oder die ergriffenen Präventionsmassnahmen.
Grundsätzlich gilt: Als grobe beschreibende Übersicht über den Stand der Dinge sind Vergleiche zwischen den Ländern durchaus nützlich. Doch wer allein basierend auf solchen Vergleichen Schlüsse über den Erfolg oder Misserfolg von bestimmten politischen Massnahmen ziehen möchte, führt das Publikum bloss in die Irre, statt Orientierung zu schaffen. Nicht alles was hinkt, ist ein Vergleich.
[Ergänzung 20. März 2021: Besondere Vorsicht ist geboten bei Vergleichen, die auf einer Form von «Sammelwert» beruhen, in dem komplexe epidemiologische, soziale oder wirtschaftliche Eigenschaften quantifiziert und miteinander verrechnet werden. EIn Beispiel dafür ist der sogenannte «Oxford Stringency Index», der eine annäherende Beurteilung dessen bietet, wie einschränkend Corona-Massnahmen in verschiedenen ländern sind. Doch da die Einteilung der Massnahmen nur sehr grob erfolgt, kann es selbst zwischen zwei Ländern mit dem gleichen Wert bei einer bestimmten Messvariable wesentliche Unterschiede geben.]
Wird zu viel in eine Statistik hineingelesen?
Statistiken sollten Erkenntnisse schaffen, nicht Meinungen bestätigen. Das unterscheidet einen seriösen Umgang mit statistischen Kennzahlen von einem unseriösen. Wenn der Schluss am Anfang der Geschichte steht und die Statistik lediglich dazu dienen soll, den eigenen Argumenten mehr Gewicht zu geben, dann kann man gleich auf sie verzichten. Dasselbe gilt im Übrigen für Expertenmeinungen: Wer nur Experten befragt, die den eigenen Schluss stützen, macht es sich zu einfach.
Statistiken so aufzubereiten, dass sie aussagekräftig, verständlich und dennoch korrekt sind, ist eine Kunst. Und weil ich weiss, wie schwierig es ist, diese hohen Anforderungen zu erfüllen, ist es mir wichtig zu betonen: Die oben besprochenen Beispiele allein lassen keine Aussage über die Expertise ihrer Urheber zu. Viele der diskutierten Fehler kenne ich aus eigener Erfahrung und einige davon begehe auch ich, wenn ich unter Zeitdruck stehe. Insofern kann ich verstehen, dass nicht alles, was aus der Perspektive eines statistischen Erbsenzählers wünschenswert ist, auch umsetzbar ist – insbesondere aufgrund des enormen Zeitdrucks, dem Journalistinnen und Journalisten in der Regel ausgesetzt sind.
Dennoch erachte ich es als eine entscheidende redaktionelle Aufgabe, komplexe statistische und wissenschaftliche Informationen sauber und verständlich aufzubereiten. Denn einige Menschen schliessen aus der Existenz bestimmter Unsicherheiten fälschlicherweise auf die Abwesenheit jedweder Gewissheit – und nehmen dies als Ausrede, um ihre eigene Meinung gleichberechtigt neben eine saubere Analyse der vorhandenen, wenn auch mit Unsicherheiten behafteten, Informationen zu stellen. Umso wichtiger ist es, dass Medienhäuser ihren Angestellten genügend Zeit und Ressourcen zur Verfügung stellen, um dem entgegenhalten zu können.
Und schliesslich ist es wichtig zu erwähnen, dass es «die» perfekte Statistik nicht gibt. Was in einer Situation nützlich und informativ ist, kann im nächsten Fall komplett in die Irre führen. Das ist kein Aufruf zur Beliebigkeit, sondern zur Berücksichtigung des Kontexts, in dem eine Statistik verwendet wird. Statistiken sind wie Worte: Richtig und umsichtig eingesetzt können sie den Horizont erweitern. Wer sie fahrlässig verwendet, führt in die Irre, statt Klarheit zu schaffen.
Relevante Interessenverbindungen
Ich habe meine ersten journalistischen Erfahrungen bei der Neuen Zürcher Zeitung gemacht und veröffentliche in unregelmässigen Abständen Kommentare in Schweizer Tages- und Online-Zeitungen. Ich arbeite in der Gruppe für Angewandte Statistik an der Universität Zürich und bin Mitglied der Schweizerischen Statistischen Gesellschaft. Siehe hier für eine vollständige Liste aller Interessenverbindungen.
Anpassungen
20. März 2021: Ergänzung bzgl. «Oxford Stringency Score» unter «Werde Äpfel mit Birnen verglichen».